- 周六 21 四月 2018
- 爬虫
- starshineee
- #爬虫, #IEEE
Motivation
有一次拿到了一列论文的信息,需要从 IEEE 上批量下载。然而大家知道,直接一个个地手动下载是一件很痛苦的事情,于是本人便写了这个爬虫,用于根据 doi 对论文自动下载。一个难点是 IEEE 采用了 ajax 加载页面的方法来防爬虫,如何解决这种问题是本文的主要关注点。
爬虫思路
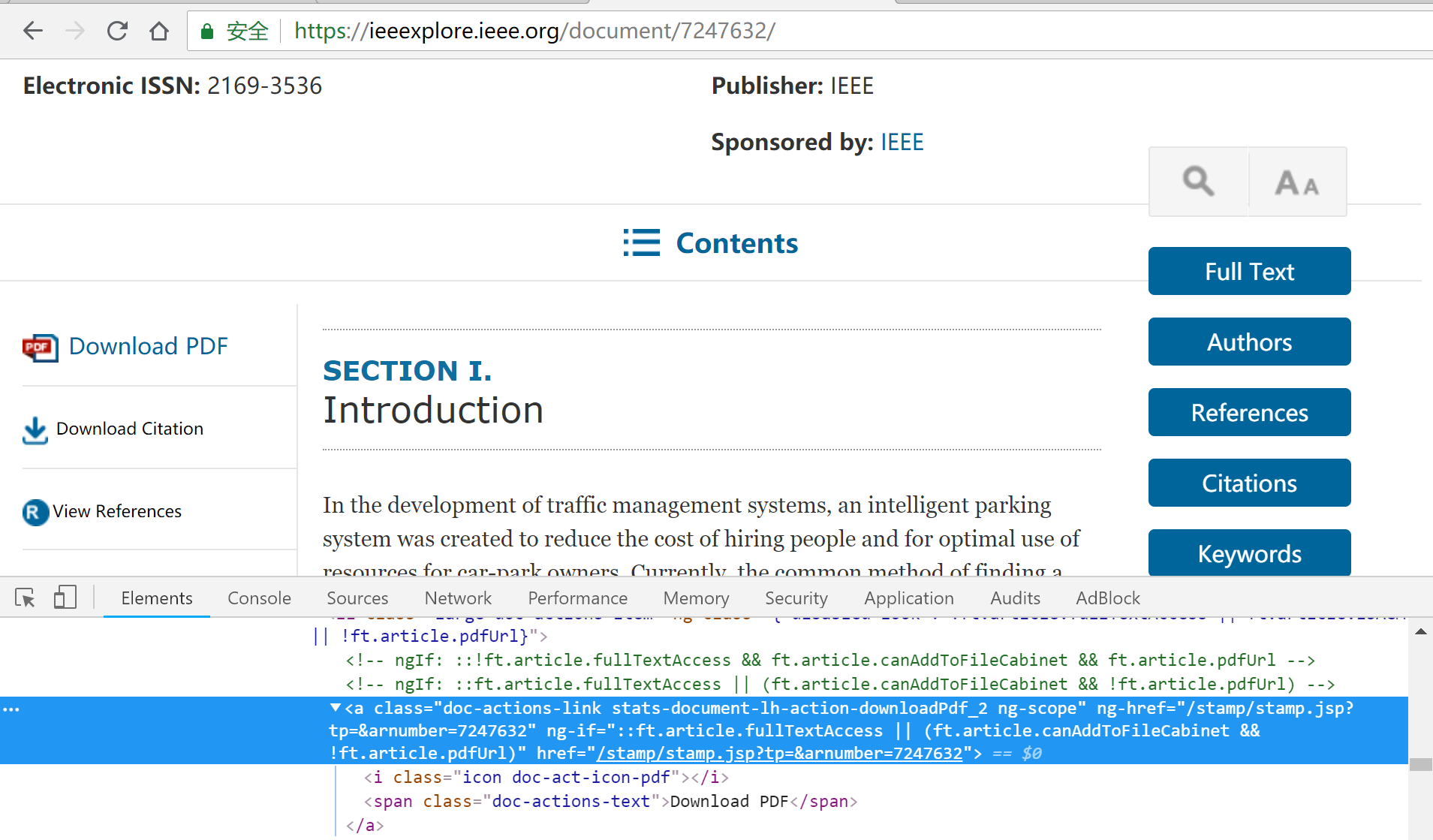
首先需要对 IEEE 网页进行分析,随便打开一个论文可以发现,其中每个论文的 doi 和 article number 是唯一的,而通过 article number 能够得到该论文的下载链接,如下图所示
然而一些情况下我们是没有 article number 的,比如利用 IEEE 页面上的 Export 导出论文信息时,文件里面只会含一些论文名、doi 等信息。那么问题就是如何才能根据 doi 来获取 article number。我们在 IEEE 搜索栏旁边选择 Advanced Search,然后选择根据 doi 来搜索论文,这时候就能得到我们想要的论文。观察 url 栏,这就是我们获取 article number 需要访问的链接。
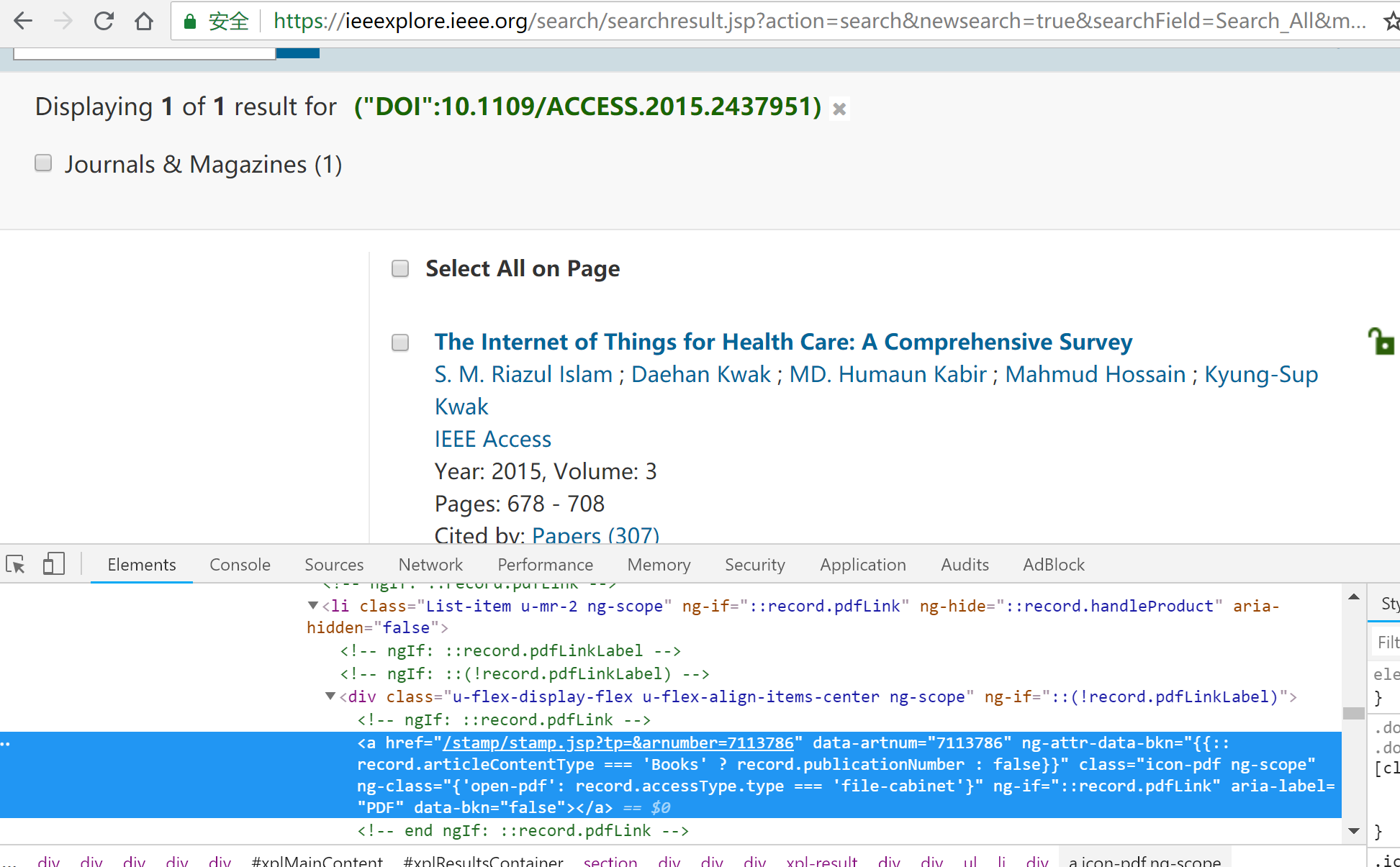
看起来似乎一切都很顺利,我们用 python 访问试试看
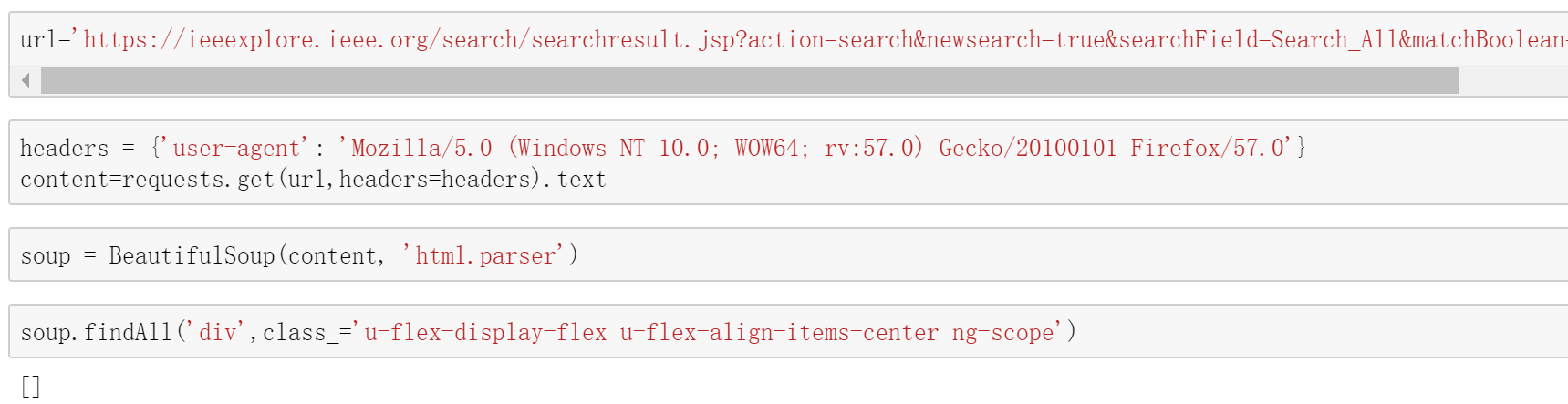
咦,为什么什么明明页面上有,却什么都没得到呢?再刷新一下网页,我们发现我们感兴趣的论文信息那部分是其它页面显示后过了一阵才刷出来的。这是因为 IEEE 用了 ajax 慢加载的方式来防止爬虫爬取页面,直接访问链接并不能得到任何东西。
对于这种问题我们可以使用工具 selenium 来解决。selenium 是一种自动化测试的工具,可以控制浏览器来自动完成一些动作,在这里正好能成为 ajax 防爬的克星。
from selenium import webdriver
browser = webdriver.Chrome('C:\Program Files (x86)Google\Chrome\Application\chromedriver.exe') # 此处改为你自己的 chromedriver 路径
urlBase='https://ieeexplore.ieee.org/search/searchresult.jsp?action=search&newsearch=true&searchField=Search_All&matchBoolean=true&queryText="DOI":'
url=urlBase+doi
browser.get(url)
time.sleep(5)
link_list=browser.find_element_by_xpath("//*[@data-artnum]")
这样 selenium 就会自动打开 chrome 从而获得 article number,你可以看到你的 chrome 在不停地加载新的页面。
但是当我们拿到 article number 后,直接 request "https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=7113786" 依然无法获得 想要的 PDF 文件。这依然是由于 IEEE 的防爬策略。事实上,访问这个 url 返回的是一个页面。观察这个返回值的结构,我们可以看到

试着访问这个链接,发现这个就是通向 pdf 的链接,成功了!
具体代码
假如你看到了这里,那说明你对于技术有一定的兴趣。爬取页面的大致思路如上文所述,具体的代码要复杂一些,可以到我的github页面上去下载。
本博客不定期更新,主要内容为爬虫、大数据、各种小工具等技术问题,欢迎到 github 上 follow 我。